23 KiB
Introduction
Walk along the trees of Madrid is a book in the An Algoliterary Publishing House: making kin with trees.
The author of this book is the Markov chains algorithm. It simultaneously generates a poem and a walk along the trees of the neighbourhood Las Letras in the centre of Madrid.
The poem is created from a novel chosen by the reader. The reader has the choice between two novels by great Spanish writers of the 19th century:
- The Swan of Vila Morta by the feminist writer Emilia Pardo Bazán published in 1891.
- Marianela by the writer Benito Pérez Galdós, published in 1878.
The walk is generated from the database with trees in Madrid, Un Alcorque, un Árbol. Each significant word - noun, adjective, verb or adverb - is related to a tree in Madrid's neighbourhood las Letras. The other words create the path between the different trees. Thus one can walk through the neighbourhood reciting parts of the poem to each tree along the promenade.
This book is by definition infinite and unique.
It is created by Anaïs Berck. It is a pseudonym that represents a collaboration between humans, algorithms and trees. Anaïs Berck explores the specificities of human intelligence in the company of artificial and plant intelligences.
An Algoliterary Publishing is a collection of publications in which algorithms are the authors of unusual books. This book was created as part of a residency at the center for contemporary arts Medialab Prado in Madrid. The residency was granted by the programme "Residency Digital Culture" initiated by the Flemish Government.
In this work Anaïs Berck is represented by:
- the Markov chains algorithm, of which a description is given in this book,
- the trees of Madrid, which are geolocated between Medialab Prado, Plaza del Sol and Atocha Renfe, and present in the database Un Alcorque, un Árbol,
- the human beings Emilia Pardo Bazán, Benito Pérez Gáldos, Jaime Munárriz, Luis Morell, An Mertens, Eva Marina Gracia, Gijs de Heij, Ana Isabel Garrido Mártinez, Alfredo Calosci, Daniel Arribas Hedo.
Poem & Walk
General description of the Markov Chains
Sources
https://spectrum.ieee.org/andrey-markov-and-claude-shannon-built-the-first-language-generation-models http://langvillea.people.cofc.edu/MCapps7.pdf https://www.irishtimes.com/news/science/that-s-maths-andrey-markov-s-brilliant-ideas-are-still-bearing-fruit-1.3220929 http://www.alpha60.de/research/markov/DavidLink_TracesOfTheMouth_2006.pdf
Histories
Andrey Andreyevich Markov was a Russian mathematician who lived between 1856 and 1922. His most famous studies were with Markov chains, an algorithm that allows to predict future changes once one knows the current state . The first paper on the subject was published in 1906. He was also interested in literature. He tried establishing a linguistic mathematical model using Markov Chains by manually counting letters of Alexander Pusjkins verse novel Eugene Onegin. Next, he applied the method to the novel Childhood Years of Bagrov's Grandson by S.T. Aksakov. This links the Markov Chains directly to the field of literature, text and language. And the link will live firmly throughout the history of this algorithm.
The following text is based on Oscar Schwartz' article for IEEE Spectrum, Andrey Markov & Claude Shannon Counted Letters to Build the First Language-Generation Models.
In 1913, Andrey Markov sat down in his study in St. Petersburg with a copy of Alexander Pushkin’s 19th century verse novel, Eugene Onegin, a literary classic at the time. This work comprises almost 400 stanzas of iambic tetrameter. Markov, however, did not start reading Pushkin’s famous text. Rather, he took a pen and piece of drafting paper, and wrote out the first 20,000 letters of the book in one long string of letters, eliminating all punctuation and spaces. Then he arranged these letters in 200 grids (10-by-10 characters each) and began counting the vowels in every row and column, tallying the results.
In separating the vowels from the consonants, Markov was testing a theory of probability that he had developed in 1906 and that we now call a Markov Process or Markov Chain. Up until that point, the field of probability had been mostly limited to analyzing phenomena like roulette or coin flipping, where the outcome of previous events does not change the probability of current events. But Markov felt that most things happen in chains of causality and are dependent on prior outcomes. He wanted a way of modeling these occurrences through probabilistic analysis.
Language, Markov believed, was an example of a system where past occurrences partly determine present outcomes. To demonstrate this, he wanted to show that in a text like Pushkin’s novel, the chance of a certain letter appearing at some point in the text is dependent, to some extent, on the letter that came before it.
To do so, Markov began counting vowels in Eugene Onegin, and found that 43 percent of letters were vowels and 57 percent were consonants. Then Markov separated the 20,000 letters into pairs of vowels and consonant combinations. He found that there were 1,104 vowel-vowel pairs, 3,827 consonant-consonant pairs, and 15,069 vowel-consonant and consonant-vowel pairs. What this demonstrated, statistically speaking, was that for any given letter in Pushkin’s text, if it was a vowel, odds were that the next letter would be a consonant, and vice versa.
Markov used this analysis to demonstrate that Pushkin’s Eugene Onegin wasn’t just a random distribution of letters but had some underlying statistical qualities that could be modeled. The enigmatic research paper that came out of this study, entitled An Example of Statistical Investigation of the Text Eugene Onegin Concerning the Connection of Samples in Chains was not widely cited in Markov’s lifetime, and not translated to English until 2006. Markov was forced to stop his letter-counting experiments, when he had nearly completely lost his sight due to glaucoma. Even if Markov had had more time and better eyesight to carry his experiments further, extensions would have been very difficult to complete, given the precomputer era he lived in, when computational efforts had to be paid in man-years.

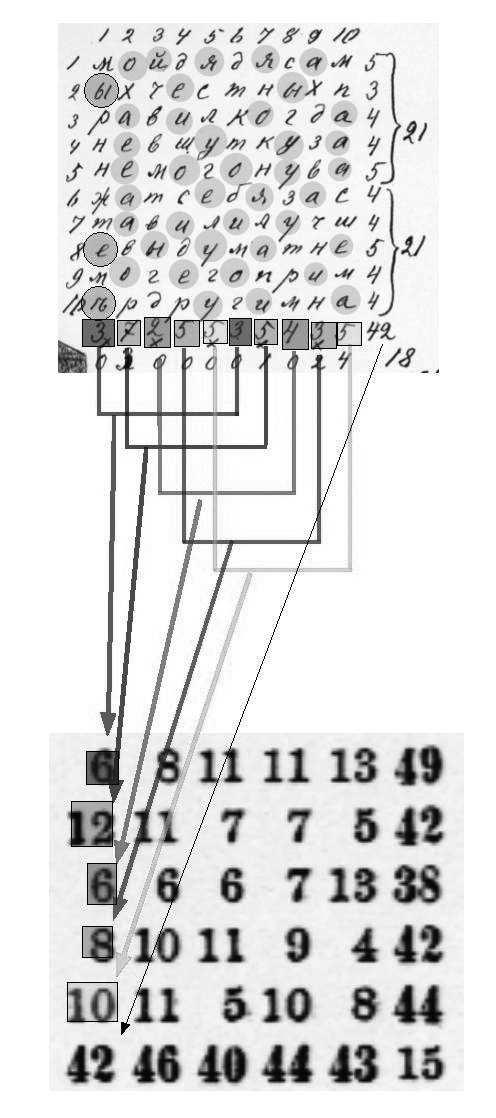
These images show Markov’s original notes in computing the probabilities needed for his Pushkin chain.
Influence
Some of Markov's central concepts around probability and language spread across the globe, eventually finding re-articulation in Claude Shannon’s hugely influential paper, A Mathematical Theory of Communication which came out in 1948.
Shannon’s paper outlined a way to precisely measure the quantity of information in a message, and in doing so, set the foundations for a theory of information that would come to define the digital age. Shannon was fascinated by Markov’s idea that in a given text, the likelihood of some letter or word appearing could be approximated. Like Markov, Shannon demonstrated this by performing some textual experiments that involved making a statistical model of language, then took a step further by trying to use the model to generate text according to those statistical rules.
In an initial control experiment, he started by generating a sentence by picking letters randomly from a 27-symbol alphabet (26 letters, plus a space), and got the following output:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
The sentence was meaningless noise, Shannon said, because when we communicate we don’t choose letters with equal probability. As Markov had shown, consonants are more likely than vowels. But at a greater level of granularity, E’s are more common than S’s which are more common than Q’s. To account for this, Shannon amended his original alphabet so that it modeled the probability of English more closely—he was 11 percent more likely to draw an E from the alphabet than a Q. When he again drew letters at random from this recalibrated corpus he got a sentence that came a bit closer to English.
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL.
In a series of subsequent experiments, Shannon demonstrated that as you make the statistical model even more complex, you get increasingly more comprehensible results. Shannon, via Markov, revealed a statistical framework for the English language, and showed that by modeling this framework—by analyzing the dependent probabilities of letters and words appearing in combination with each other—he could actually generate language.
The more complex the statistical model of a given text, the more accurate the language generation becomes—or as Shannon put it, the greater “resemblance to ordinary English text.” In the final experiment, Shannon drew from a corpus of words instead of letters and achieved the following:
THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER THAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED.
For both Shannon and Markov, the insight that language’s statistical properties could be modeled offered a way to re-think broader problems that they were working on. For Markov, it extended the study of stochasticity beyond mutually independent events, paving the way for a new era in probability theory. For Shannon, it helped him formulate a precise way of measuring and encoding units of information in a message, which revolutionized telecommunications and, eventually, digital communication. But their statistical approach to language modeling and generation also ushered in a new era for natural language processing, which has ramified through the digital age to this day. As David Link notes in his article, Traces of the Mouth, Markov's efforts in retrospect “represent an early and momentous attempt to understand the phenomenon of language in mathematical terms.” It's not an exaggeration to say that Markov's analysis of text is in principle similar to what Google and other firms now routinely carry out on a massive scale: analyzing words in books and internet documents, the order in which the words occur, analyzing search phrases, detecting spam and so on.
Applications
Since Markov chains can be designed to model many real-world processes, they are used in a wide variety of situations. They appear in physics and chemistry when probabilities are used for unknown quantities. In information processing, they have a role in pattern recognition, automatic speech analysis and synthesis and data compression. They are used by meteorologists, ecologists and biologists. Other applications include the control of driverless cars, machine translation, queuing patterns, and prediction of population growth, asset prices, currency exchange rates and market upheavals. Also artists have used Markov chains, such as musician Iannis Xenakis who developed “Free Stochastic Music” based on Markov chains.
In 2006 – the 100th anniversary of Markov's paper – Philipp Von Hilgers and Amy Langville summarized the five greatest applications of Markov chains. This includes the one that is used by most of us on a daily basis, Google's Page Rank. Every time we search on the internet, the ranking of webpages is based on the solution to massive Markov chain. You can say that all the web pages are states, and the links between them are transitions possessing specific probabilities. In other words, we can say that no matter what you’re searching on Google, there’s a finite probability of you ending up on a particular web page. If you use Gmail, you must’ve noticed their Auto-fill feature. This feature automatically predicts your sentences to help you write emails quickly.
And last but not least, have you ever wondered why spam has all those hilarious nonsensical strings of words in it? They’re pretty odd constructions, not as random as if you picked words randomly out of a hat, almost grammatical much of the time, but still clearly gibberish. Also here the Markov chains have taken on a lot of the work.
Technical description of the Markov Chains
Sources
https://en.wikipedia.org/wiki/Examples_of_Markov_chains https://higherkindedtripe.wordpress.com/2012/02/26/markov-chains-or-daddy-where-does-spam-come-from/ https://towardsdatascience.com/predicting-the-weather-with-markov-chains-a34735f0c4df
In a Markov process we can predict future changes once we know the current state. Wikipedia gives a very good description of the difference between Markov chains and other systems: 'A game of snakes and ladders or any other game whose moves are determined entirely by dice is a Markov chain, indeed, an absorbing Markov chain. This is in contrast to card games such as blackjack, where the cards represent a 'memory' of the past moves. To see the difference, consider the probability for a certain event in the game. In the above-mentioned dice games, the only thing that matters is the current state of the board. The next state of the board depends on the current state, and the next roll of the dice. It doesn't depend on how things got to their current state. In a game such as blackjack, a player can gain an advantage by remembering which cards have already been shown (and hence which cards are no longer in the deck), so the next state (or hand) of the game is not independent of the past states.'
So, for a Markov process, only the current state determines the next state; the history of the system has no impact. For that reason we describe a Markov process as memoryless. What happens next is determined completely by the current state and the transition probabilities.
In what follows, we describe a classic working of the Markov chains, next to a simplified version we used to develop a Markov game and the code for this book.
Classic version
This example is taken from the following source: https://higherkindedtripe.wordpress.com/2012/02/26/markov-chains-or-daddy-where-does-spam-come-from/
You take a piece of “training” text.
You make a list of all the words in it.
For each word, make a list of all the other words that come after it, with the number of times each word appears. So with the sentence: “the quick brown fox jumped over the lazy dog”, you would end up with the list:
- the -> (1, quick), (1, lazy)
- quick -> (1, brown)
- brown -> (1, fox)
- fox -> (1, jumped)
- jumped -> (1, over)
- over -> (1, the)
- lazy -> (1, dog)
- dog ->
Turn the list into a matrix, where the rows represent the “leading” words and the columns represent “following” words, and each number in the matrix says how many times the following word appeared after the leading word. You will get:
| the | quick | brown | fox | jumped | over | lazy | dog | |
|---|---|---|---|---|---|---|---|---|
| the | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| quick | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| brown | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| fox | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| jumped | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| over | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| lazy | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| dog | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Divide every number in the matrix by the total of its row, and you’ll notice that each row becomes a sort of probability distribution.
| the | quick | brown | fox | jumped | over | lazy | dog | |
|---|---|---|---|---|---|---|---|---|
| the | 0 | 0.5 | 0 | 0 | 0 | 0 | 0.5 | 0 |
| quick | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| brown | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| fox | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| jumped | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| over | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| lazy | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| dog | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
You can interpret this as saying “if the first word is a ‘the’ there’s a 50% chance the next word is ‘quick’, and a 50% chance the next word is ‘lazy’. For all the other words, there is only one possible word following it.”
Almost every word has only one possible following word because the text is so short. But, if you train it with a larger text, and interpret the rows as a probability distribution, you can start to see for every word what sort of word tends to follow it. This gives a very interesting insight into the nature of written text.
If you take that big “transition matrix” you’ve trained from a large text, you can use it to actually generate new text in the following way:
-
Pick a “seed” word from the text at random. For best results use one with many possible following words.
-
Find the row in the matrix corresponding to that word. Choose the next word at random, weighted according to the probabilities in the row. That is, if the column corresponding to the word “blue” has the number .05 in it, you have a 5% chance of picking “blue” as the next word, and so on (when we divided each number by the total of its row we made sure that these probabilities would add up to 1).
-
Go back to step 2 using this second word as the new “seed” word. Continue this process to generate as long a string of words as you want. If you end up with a word for which no other words follow it (uncommon when you train on a large test, but possible – imagine if the last word of a novel was the only occurrence of the word “xylophone”, or whatever), just pick a random word.
You can see how strings of words generated with this method will follow the “trends” of the training data, meaning that if you were to generate a new transition matrix from the generated words it would, on average, look the same as the original transition matrix since you picked the words according to those weights. This completely mechanical process can generate data which looks, statistically, like meaningful English. Of course, it is not necessarily grammatical, and is certainly devoid of higher meaning since it was generated through this simplistic process.
Those “chains” of words constructed by the above process are an example of Markov chains. And they are also the answer to the question “where does spam come from?”. Those uncannily-almost-grammatical ramblings below the “Viagra” ads, generated through the above process, are the spam-creators way of fooling your spam filter. They include these chains to give their advertisements statistical similarity to meaningful human correspondence. This works because the spam filters are (at least in part) using probabilistic models that depend on word-transitions and word frequencies to classify incoming email as spam. The spammers and the filter-writers are engaged in an eternal game of randomly-generated cat-and-mouse.
Simplified version
With Algolit, an artistic research group on libre code and text based in Brussels, we developed a Markov Chain game with sentences and cards. This happened as part of the festival Désert Numérique, in La Drôme in France in 2014. The game was developed by Brendan Howell, Catherine Lenoble and An Mertens. You can listen back to the radio show: http://desert.numerique.free.fr//archives/?id=1011&ln=fr.
Next, the game was presented at Transmediale in Berlin in 2015, respecting the following rules.
- We take a text, for example:
Cqrrelations read as poetry to statisticians. Can statisticians read poetry with machines?Cqrrelations is a practise for artists, for datatravellers, statisticians and other lovers of machines to explore a world of blurry categorisations and crummylations. Machines correlate to dissidents, dissidents correlate to statisticians.
-
We create a database for this text; each word is an entry and takes the following word as a possible value. The entry for ‘Cqrrelations’ will have two values:
- read
- is
-
Once the database is created, we choose a starting word for a new text, for ex. Cqrrelations.
-
We roll the dice, odd numbers will give ‘read’ as the 2nd word of our text; even numbers will give ‘is’ as the 2nd word.
-
We roll the dice again, and choose a word amongst the values of the chosen word. This gives the next word of our sentence.
-
We continue 5 till we arrive at a word with a period (.)
-
We can repeat rule 3 till 6 until we are satisfied with the amount of generated sentences
Based on the input text the output at Transmediale was:
A world of blurry categorisations and other lovers of blurry categorisations and other lovers of blurry categorisations and other lovers of machines. Cqrrelations read poetry to dissidents correlate to machines. Lovers of machines to statisticians.
Code of the book
Credits
This book is a creation of Anaïs Berck for Medialab as part of the programme "Residency Digital Cultur" initiated by the Flemish Government. In this work Anaïs Berck is represented by:
- the Markov chains algorithm, of which a description is given in this book,
- the trees of Madrid, which are geolocated between Medialab Prado, Plaza del Sol and Atocha Renfe, and present in the database Un Alcorque, un Árbol,
- the human beings Emilia Pardo Bazán, Benito Pérez Gáldos, Jaime Munárriz, Luis Morell, An Mertens, Eva Marina Gracia, Gijs de Heij, Ana Isabel Garrido Mártinez, Alfredo Calosci, Daniel Arribas Hedo.
The copy of this book is unique and the print run is by definition infinite.
This copy is the XXX number of copies downloaded.
Collective terms of (re)use (CC4r), 2021
Copyleft with a difference: You are invited to copy, distribute, and modify this work under the terms of the work under the terms of the CC4r.